Can analytics help us identify critically acclaimed movies?
I have always been a fan of all the Hollywood classics that are so deeply ingrained in American culture. Casablanca, The Bridge on the River Kwai, Star Wars, Jaws, and many other movies are staples of American cinema. Production companies often have trouble creating a quality movie even with enormous budgets. Production companies would sign famous actors and directors to attract a bigger audience, but often these two factors does not guaranetee that a movie will be well received by the audience. I was curious to see if there was any way we can predict the score of a movie before it is released. Therefore, I decided to look at the web for data and see which factors contribute in producing a quality movie.
I started by scraping data from the http://www.boxofficemojo.com/ and http://www.imdb.com/. Luckily, there was already a data set on Kaggle that scraped all the important features of a movie from http://www.imdb.com/. I ended up with 5000 movies with 30 features such as budget, actors, actresses, movie facebook likes, year of release, country of origin, gross, duration, MPAA rating, and many more.
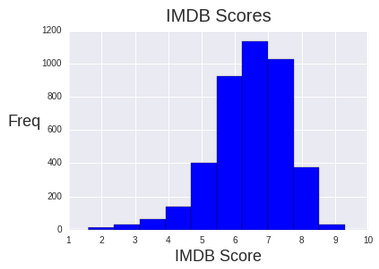
I first looked at the distribution of the IMDB scores to see how the ratings were overall. The median score was 6.6 with the top 250 movies having a score higher than 8.
I tested out these features with a linear regression model and only achieved a R-squared value of 27.7%. I tested the data with other models such as ridge models, adaptive boosting, lasso models, random forests, and gradient boosted regression. My best model was from using gradient boosted regression that achieved a R-squared value of 42.6% which still isn’t great, but at least it’s an improvement from the linear regression model. I introduced random noise into the model so I can throw out the features that aren’t important. After running my random forest model several times with the random noise I found out that the most important features in determining the IMDB score were movie facebook likes, director facebook likes, duration, and the budget of the film. THe graphs below show the relationship of the IMDB Score with some of these features.
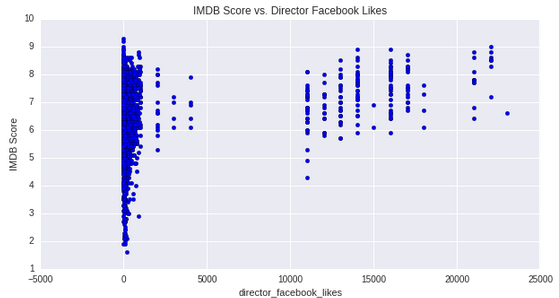
It’s interesting to note that the directors with the highest facebook likes would generally make quality movies.
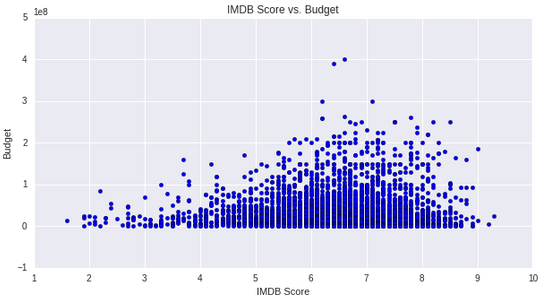
Notice that movies with a budget of lower than 200 million dollars would never score higher than a 6.
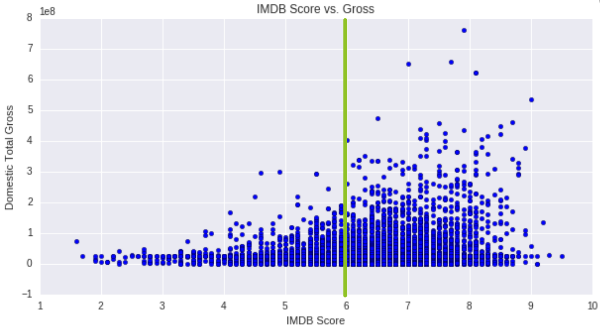
The graph below shows how gross and score are related. The green line shows that there aren’t any movies with a score less than 6 gross more than 300 million dollars.
I also tried some feature engineering. I made a dummy variable for the MPAA ratings and genres. I also thought that directors who had many movies in their resume would mean that they would consistently produce quality movies. I made a dummy variable for rank of directors based on how many movies they had in the data. However, there was not an improvement after running the models with these features. In the end, I found out that social media following has some effect on the rating of a movie. I was suprised to see that actors do not significantly affect the score of a movie which makes sense if you think about it. There have been many times where I watched a movie just for the stellar cast, but ended up being disappointed because the movie was horrible.
In conclusion, I realized that predicting the score of a movie is difficult because our opinion on a movie is difficult to quantify. A movie can look great on paper with a great cast and director, but still end up being a disaster.